

In the data-driven world, modern enterprises are shifting their on-premises big data to cloud computing infrastructure platforms to enable digital business transformation. Furthermore, with COVID-19 still hanging on, the cloud shift is accelerating at breakneck speed as organizations look to improve their operational efficiencies.
Nonetheless, in today’s rapidly changing business environment, just the migration of a massive amount of data onto the cloud is not enough to achieve digital transformation. The data migrated on the cloud platform needs to be processed, managed and automated. Microsoft’s Azure Data Factory (ADF) is one such platform that enables organizations to solve all such data-related scenarios.
But before turning towards the adoption of an instantly scalable cloud environment – ADF, you must be aware of a set of best practices to implement it. If you are looking for relevant best practices to implement Azure Data Factory services then this blog post is for you.
What are the best Azure Data Factory implementation practices
Here are some Azure Data Factory best practices that can help you to orchestrate, process, manage and automate the movement of big data.
1. Set up a code repository for the data
To get an end-to-end development and release experience, you must set up a code repository for your big data. Azure Data Factory enables you to set up a Git repository using either GitHub or Azure Repos to manage all your data-related tasks and keep all your changes. You can attach a code repository to ADF from two places:
1. Main Dashboard – Click on the “Set up Code Repository” button on the Azure Data Factory home page.

2. Authoring Canvas – Go to the “Data Factory” dropdown menu and select the “Set up Code Repository”.
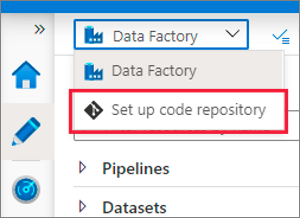
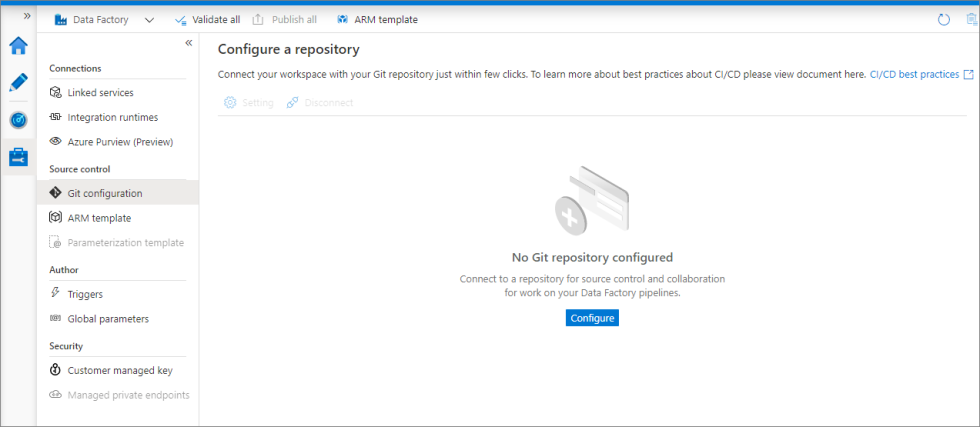
3. Management Hub – Go to the “Source Control” section. Select the “Git Configuration” and click on the “Configure” button.
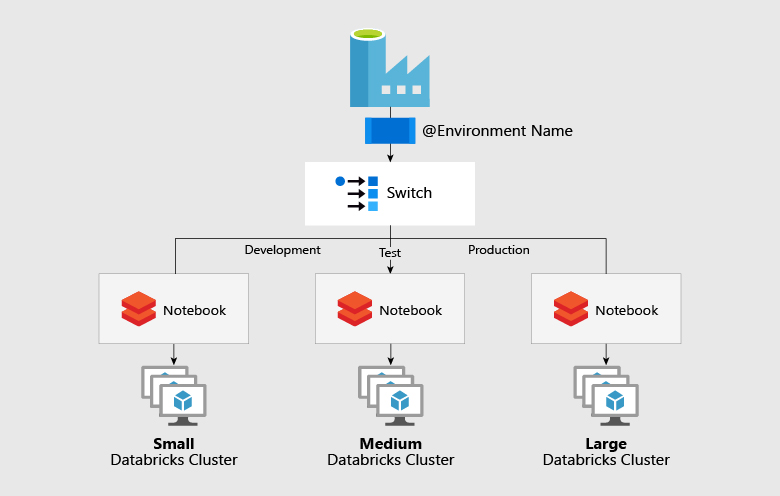
2. Toggle between different environment set-up
A data platform contains different environments like development, production and test. And the amount of computing differs in each environment. So, to handle workloads of different environments, separate data factories are required. But, Azure Data Factory enables you to handle different environment set-ups via a single data platform using the ‘Switch’ activity. Each environment is configured with a different job cluster that is connected to central variable control to switch between different activity paths. Visually, it may look something like the image below:
3. Go for good naming conventions
It is crucial to understand the purpose and importance of having good naming conventions for any resource. When applying naming conventions, you must know which characters you can use and which characters you cannot use. For instance, when you are naming components, you must make sure that you do not include spaces or things from names that could break the JSON expression. Microsoft has laid certain naming rules for the Azure Data Factory, as shown in the table below:
| Name | Name Uniqueness | Validation Checks |
| Data Factory | Must be unique across Microsoft Azure. They are case-insensitive. |
• Object names must start with a letter or a number. Can contain only letters, numbers and the dash (-). • Every dash character must be immediately preceded and followed by a letter or a number. • Length: 3 to 63 characters. |
| Linked Services/Pipelines/Datasets/Data Flows | Must be unique within a data factory. They are case-insensitive. |
• Object names must start with a letter. • The following characters are not allowed: “.”, “+”, “?”, “/”, “<”, ”>”,”*”,”%”,”&”,”:”,”\” • Dashes (-) are not allowed. |
| Integration Runtime | Must be unique within a data factory. They are case-insensitive. |
• Name can contain only letters, numbers and the dash (-). • The first and last characters must be a letter or number. • Consecutive dashes are not permitted. |
| Pipeline Parameters | Must be unique within a pipeline. They are case-insensitive. |
• Follow data flow transformation naming rules to name your pipeline parameters and variables. • Validation check on parameter names and variable names is limited to uniqueness. |
| Data Flow Transformation | Must be unique within a data flow. They are case-insensitive. |
• Names can only contain letters and numbers. • The first character must be a letter. |
4. Link Azure Key Vault for security
To add an extra layer of security, the best practice is to link Azure Key Vault to Azure Data Factory. Azure Key Vault allows you to store the credentials securely in it for carrying out data storage/computing. Linking the Azure Key Vault will enable you to retrieve secrets from it using the key vault’s own Managed Service Identity (MSI). To reference a credential stored in the Key Vault, you can even create a linked service pointing towards the vault. Also, it is recommended to key vaults for different environments.
5. Implement automated deployments (CI/CD)
One of the significant things in Azure Data Factory is to know how to implement automated deployments for continuous integration and continuous deployment. To deploy Azure Data Factory, you can either use ARM templates or JSON definition files and PowerShell cmdlets. However, before implementing Azure Data Factory deployments, you must have answers to these questions:
- Which source control tool to use?
- What is your code branching strategy?
- What deployment method we wish to use?
- How many environments are required?
- What artifacts are we going to use?
6. Consider automated testing
The Azure Data Factory implementation is incomplete without considering testing. Automated testing is a core element of CI/CD deployment approaches. In ADF, you must consider performing end-to-end testing on connected repositories and all your ADF pipelines in an automated way. This will help you to monitor and validate the execution of each activity of the ADF pipeline.
Start laying the groundwork
If you want to build a modern data architecture using Azure Data Factory, then you must follow the best practices mentioned in this blog post. Moreover, our certified data experts and Azure Data Factory developers can help you to implement the Azure cloud platform along with transforming, ingesting and copying your big data to the cloud.






