
Customer Background
Our client is a leading provider of high-precision industrial components, serving a diverse range of industries including automotive, aerospace, and medical. Founded in 1975, the company has grown steadily by adhering to strict quality standards and continuous innovation.
-
Industry
Manufacturing
-
Technologies / Platforms / Frameworks
Python, SQL, Databricks, Power BI Modelling
Challenges
The client was facing significant challenges due to the sheer volume and complexity of their data. They struggled to keep pace with the growing data volume, leading to slow processing times and limited scalability.
Data volume and complexity:
- Terabyte-scale data: The company generates massive amounts of supply chain data from various other sources. Managing this volume and ensuring its integrity was a significant challenge.
Data processing and analytics:
- Slow processing: They used traditional data platforms like Synapse and Azure Data Factory (ADF). They struggled to process large datasets efficiently, hindering timely insights generation and decision making.
- Limited scalability: They were not able to scale efficiently with increasing data volume, leading to performance bottlenecks and operational issues.
- Complex data pipelines: Extracting, transforming, and loading (ETL) data from diverse sources was complex and time-consuming.
- Third-party dependence: Synapse and ADF required third-party APIs to write business logic, introducing additional complexity and vendor lock-in.
Data storage and management:
- Cost optimization: Storing and managing massive datasets had become expensive. It required careful planning and resource allocation.
- Data accessibility: Making data readily available to various stakeholders across the organization was challenging. It required robust data access management policies and tools.
Data insights and action:
- Extracting meaningful insights: They lacked advanced analytics techniques and expertise in data science required to identify valuable patterns and trends from massive datasets.
- Actionable insights: It was difficult to derive actionable insights from data and translating them into practical business decisions.
- Real-time decision making: It was challenging to make data-driven decisions in real time with latency issues and complex data pipelines.
- Compliance: Complying with GDPR’s strict data privacy regulations was mandatory, but cross-region data sharing was disabled, hindering global collaboration.
Solutions
Softweb Solutions’ team adopted a comprehensive consulting approach tailored to the client’s specific needs. Our data experts implemented Databricks, leveraging its savvy features to significantly improve the telecom company’s data management, analytics, and decision-making capabilities.
- Unified data processing: With Databricks, we unified data warehousing and data lake functionalities, allowing seamless processing of both structured and unstructured data.
- Advanced data processing engine: Apache Spark engine provides superior performance for processing massive datasets, significantly reducing processing times.
- Data transformation and processing:
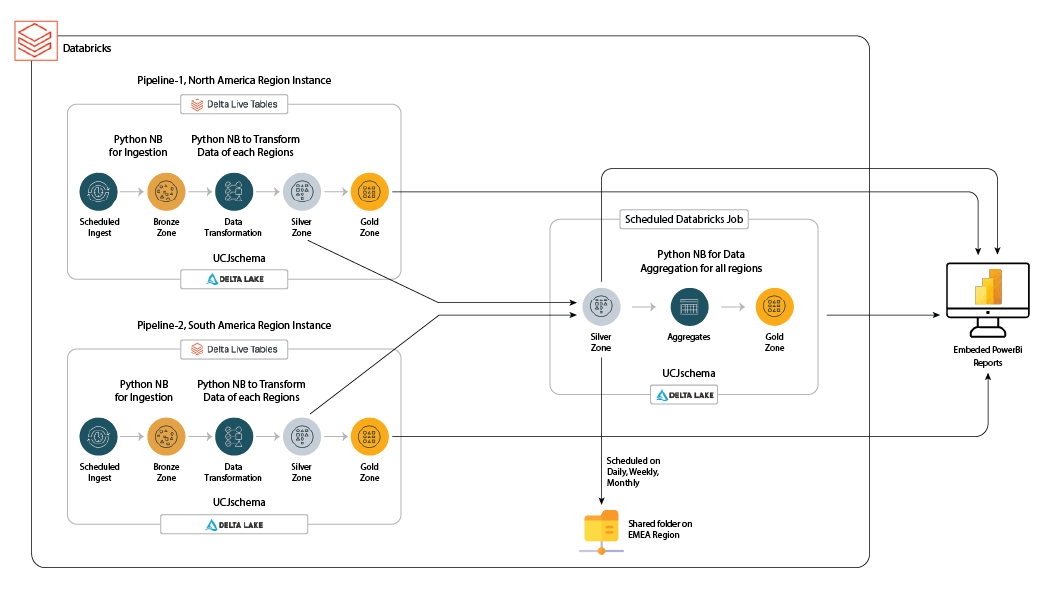
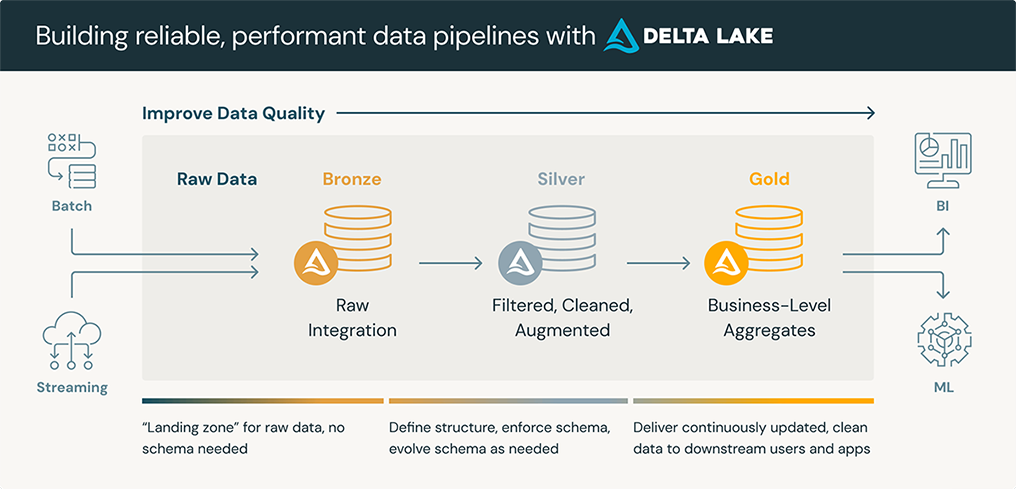
- Medalion architecture: Implemented the industry-standard medallion architecture for data organization and processing.
- Bronze layer: Ingested raw table data directly into the pipeline for efficient storage.
- Silver layer: Mapped, joined, and filtered data from the Bronze layer to create structured and dimensional tables.
- Gold layer: Used star schema with dimensional and factual tables to unify regional data into a central repository (warehouse).
- Single notebook transformation: Databricks allows data transformation within a single notebook using Python and other supported languages, simplifying the development process, and improving code maintainability.
- Virtualized clusters: Our data experts created clusters using Databricks that act like virtual machines. It automatically initiates with the same configuration only when needed and shuts down when idle, optimizing resource utilization and reducing costs.
- Cross-region data sharing: Databricks enables seamless data sharing across different regions, facilitating collaboration and data access for geographically dispersed teams.
- Data security and compliance: This solution provides robust security features and compliance certifications to ensure data protection and regulatory adherence.
- Power BI reporting: We leveraged Power BI’s user-friendly interface to create compelling reports, track KPIs.
- Real-time decision support: Databricks’ real-time analytics capabilities enable the client to base their decisions on the latest data insights, ensuring agility and responsiveness in a competitive landscape.
Benefits
- Reduced processing time: Accelerated the client’s ETL process, significantly improving their time to insights.
- Enhanced scalability: The client’s data infrastructure now seamlessly scales with their growing data volume, allowing them to embrace new data sources and advanced analytics.
- Improved cost efficiency: Transitioning to Databricks significantly reduced the client’s data analytics costs, freeing up resources for other strategic initiatives.
- Increased operational efficiency: Databricks streamlined the client’s data pipeline, improving overall data management and operational efficiency.
| Feature | Databricks | Synapse | Azure Data Factory |
|---|---|---|---|
| Big data processing | Built-in Apache Spark engine provides unparalleled performance and scalability for petabyte-scale data processing. | SQL Data Warehouse engine struggles with large data volumes and complex transformations. | Not designed for big data: Focuses on data integration and orchestration, not heavy processing. |
| Machine learning | Comprehensive ML libraries and tools for building, deploying, and managing models. | Basic ML capabilities for simple tasks. | Requires integration with external services like Azure Machine Learning. |
| Scalability | Elastically scales resources based on workload, ensuring optimal performance and cost-efficiency. | Horizontally scales data warehouse resources but may not be cost-effective for very large datasets. | Flexible scaling for data integration tasks, but not ideal for large-scale processing. |
| Cost-effectiveness | Pay-as-you-go: Charges based on cluster size and duration, avoiding unnecessary costs for idle resources. | Complex: Tiered pricing based on data exploration, warehousing, storage, and processing, makes cost estimation difficult. | Activity-based: Charges based on data movement and activity units, potentially incurring unexpected costs for complex pipelines. |
| Hybrid Data Integration | Integrates seamlessly with both on-premises and cloud environments. | Notable for big data and data warehousing. | Supports hybrid data integration. |
- 79%
Increased data visibility
- 11%
Increased revenue
- 64%
Reduced data processing time
Need more information?
Tell us what you are looking for and we will get back to you right away!
