One of the most important assets for any organization is its information. Traditionally, data warehousing has been the cornerstone of business intelligence (BI) and decision support. These centralized repositories excel at handling structured data, providing a consistent view for analytical processing. However, as data volumes surged, unstructured data proliferated, and the need to store multimedia content increased—so was the demand for data lakes.
Unlike data warehouses, data lakes embrace raw, unprocessed data and store it in open file formats using a schema-on-read architecture. These low-cost storage systems accommodate diverse data types without predefined schemas. However, data lakes face security, query optimization, and real-time analytics challenges. These limitations increase demand for a more structured and efficient solution like a data lakehouse.
What is a data lakehouse?
A data lakehouse combines the strengths of data warehouses and data lakes. It provides a unified platform for managing and analyzing large-scale data, handling both structured and unstructured data. This versatility enables real-time analytics and flexibility, offering agility for data management. It allows for rapid analysis via ML, SQL queries, or BI. However, its complexity demands precise implementation to avoid data inconsistencies and duplication.
A data lakehouse combines the following features:
- Flexibility: Like data lakes, it can handle diverse data formats.
- Cost-efficiency: It leverages low-cost storage.
- ACID transactions: Ensures data consistency and reliability.
- Unified access: Enables seamless querying across structured and unstructured data.
Data lakehouses were introduced in 2020, so they are still a relatively new concept. Three popular lakehouses are Delta Lake, developed by Databricks, Apache Iceberg by Netflix, and Apache Hudi by Uber.
Considering its unique architecture, organizations have high hopes from data lakehouses. With that, this blog shines a light on the concept of data lakehouses, differences between database architectures, why data lakehouses matter, the components of a data lakehouse, and how data lakehouses empower data engineering workflows.
Differences between database architectures
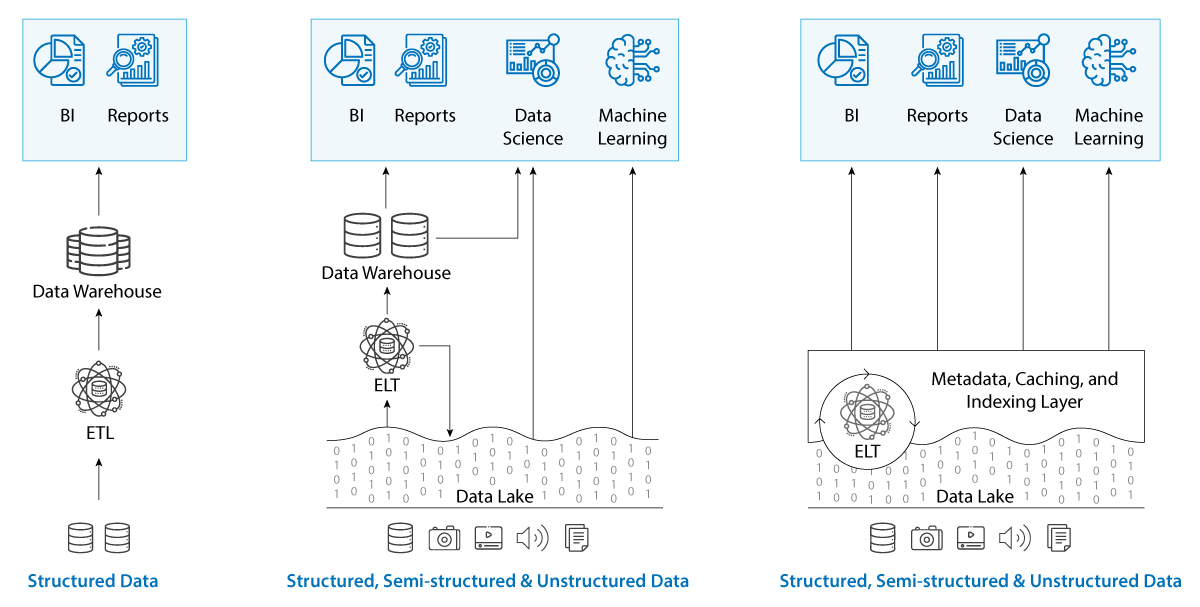
The following table summarizes the key differences between a data warehouse, a data lake, and a data lakehouse. Further, the main architectural differences between data warehouses, data lakes, and data lakehouses are visualized in the image.
| Data warehouse | Data lake | Data lakehouse | |
|---|---|---|---|
| Data |
|
|
|
| Processing |
|
|
|
| Storage |
|
|
|
| Schema |
|
|
|
| Integration |
|
|
|
| Use Cases |
|
|
|
Suggested: According to Gartner, by 2025, 75% of enterprise data will be processed outside of traditional data centers. Learn the key differences between a data lake and a data warehouse.
Why data lakehouses matter
- Unified platform: Organizations can manage structured and unstructured data within a single platform. This simplifies data governance, reduces data silos, and fosters collaboration across teams.
- Real-time analytics: Data lakehouses enable real-time analytics by allowing data engineers and data scientists to work with fresh, raw data. Whether it’s streaming data, log files, or sensor readings, lakehouse facilitates timely insights.
- Scalability: As data volumes explode, scalability becomes critical, lakehouses scale horizontally, accommodating growing datasets without compromising performance.
- Cost-effectiveness: By avoiding data duplication and optimizing storage, lakehouses minimize costs associated with data management.
Components of a data lakehouse
Unified data storage
At the heart of a data lakehouse lies its unified data storage. Here’s what you need to know:
- Storage architecture: Data resides in cloud storage (e.g., object stores) using Delta files/tables. This architecture allows for efficient data organization and retrieval.
- Medallion architecture: It offers curated data storage for efficient ELT pipelines. Think of it as your data treasure chest, where each piece of information is carefully cataloged and accessible.
Scala processing
To process the data within a lakehouse, we turn to powerful tools like:
- Apache Spark and Photon: These engines handle transformations and queries. Spark’s distributed computing capabilities ensure scalability, while Photon accelerates query performance.
- Delta Live Tables (DLT): DLT is a declarative framework for reliable data pipelines. DLT simplifies the orchestration of data transformations, making your life as a data engineer easier.
Advanced analytics
A data lakehouse is not just about storage and processing – it is about extracting valuable insights:
- SQL queries: Utilize SQL warehouses and serverless SQL warehouses. Query your data lakehouse with familiar SQL syntax.
- Data science workloads: A data lakehouse supports ML modeling, AutoML, and MLOps with MLflow. You can leverage machine learning’s power to uncover patterns and predictions.
Data governance and security
A responsible data lakehouse ensures proper governance and protection:
- Metadata layers: Delta Lake provides ACID compliance, schema evolution, and data validation. Keep your data lineage intact.
- Fine-grained access controls: Secure your data lakehouse with role-based permissions. Only authorized users should access sensitive information.
Integration with existing systems
A data lakehouse does not exist in isolation – it collaborates with your existing ecosystem:
- Lakehouse federation: Seamlessly integrates SQL sources (RDBMS) and other cloud providers. Connect your data dots.
- Streaming ingestion: Use Databricks Structured Streaming for real-time data. Keep your lakehouse up-to-date.
Exclusive Data Assessment
Time is not far when you will find data embedded in every decision, interaction, and process. To stay ahead of the curve, discover your organization’s data readiness assessment. Take the Survey to:
- Receive a personalized report
- Gain valuable insights into your organization’s data readiness
- Identify areas of improvement in data analytics journey
How data lakehouses empower data engineering workflows
The true power of a data lakehouse lies in how it empowers data engineers:
Rapid prototyping and experimentation
- With a data lakehouse, data engineers can quickly realize prototypes for new data pipelines, services, or data models. They can test these in a secure, isolated environment.
- Working with up-to-date data, data engineers respond swiftly to changing business needs. A lakehouse accelerates innovation.
Simplified workflow orchestration
- Data engineers, data scientists, and analysts can build reliable data, analytics, and ML workflows without managing complex infrastructure.
- Earlier, external tools were used for task orchestration from the data processing platform. That led to limited observability and increased complexity. Now, every user can deliver timely, accurate, and actionable insights for their business initiatives.
Scalability and performance
- Distributed processing and storage ensure high performance even as data grows. Data engineers extract insights without compromising processing speed.
- Whether it’s batch ETL, streaming, or machine learning, a lakehouse scales effortlessly to meet demands.
Holistic data management
- Centralizing disparate data sources simplifies engineering efforts. Everyone in your organization can access a single source of truth, reducing data silos and ensuring consistency.
- Data lakehouses facilitate data governance by providing a comprehensive view of data lineage, access controls, and auditing capabilities. Moreover, with a unified platform, data engineers can efficiently manage data quality, metadata, and compliance across the entire data lifecycle.
In summary, data lakehouses empower data engineering workflows by fostering agility, scalability, and holistic data management. They bridge the gap between data warehouses and data lakes, enabling organizations to harness data effectively for informed decision making.
Suggested: Data engineering workflows help build mission-critical software and architecture. Learn the basics of data engineering, from what it is to why it matters.
Conclusion
In our journey toward modern data engineering, data lakehouse emerges as a pivotal player. It empowers organizations to harness the full potential of their data, enabling real-time insights, scalability, and cost efficiency. Overall, a data lakehouse is the best option for:
- Faster data ingestion
- Quick query performance
- Strong performance across scaling scenarios
- Efficient support for different data workloads
- Consistent and competitive performance
- Handling different dataset sizes
Since a data lakehouse is a relatively new concept, many companies need help to adopt a data lakehouse because it requires specialized knowledge and skills to manage effectively. Maximizing the advantages of a data lakehouse while mitigating potential issues requires strategic planning, infrastructure investment, and a skilled data specialist team. Contact us for these essential elements and more for data lakehouse implementation and ensure its effectiveness.