Kubernetes is a container orchestration system that helps you deploy, manage, and scale containerized applications. One of the key features of Kubernetes is its ability to automatically scale your applications up or down based on demand. This is done through a mechanism called horizontal pod autoscaling.
91% respondents reported using or evaluating Kubernetes in a 2021 survey by the Cloud Native Computing Foundation (CNCF).
What is horizontal pod autoscaling?
Traditional scaling methods are often slow and inefficient, requiring manual intervention to increase or decrease the number of instances to match demand. This can be a challenge in the dynamic world of cloud-native applications, where demand can rapidly change.
Kubernetes HorizontalPodAutoscaler (HPA) automates this process, allowing you to set up rules that will automatically scale your application up or down based on CPU utilization or other metrics. This ensures that your application remains responsive while avoiding overprovisioning or underutilization of resources.
Horizontal pod autoscaling works by monitoring specific resource metrics, such as CPU utilization or memory consumption, and adjusting the number of pod replicas to maintain a target metric value. When resource usage crosses a predefined threshold, Kubernetes scales the deployment up or down, ensuring that the application’s performance remains within acceptable limits.
Key benefits of using horizontal pod autoscaling:
Kubernetes horizontal pod autoscaling offers numerous business benefits, including cost savings, improved application performance, high availability and reduced manual intervention. By automatically adjusting resources based on demand, HPA empowers your applications to efficiently handle varying workloads while maintaining a positive user experience.
How does horizontal pod autoscaling work?
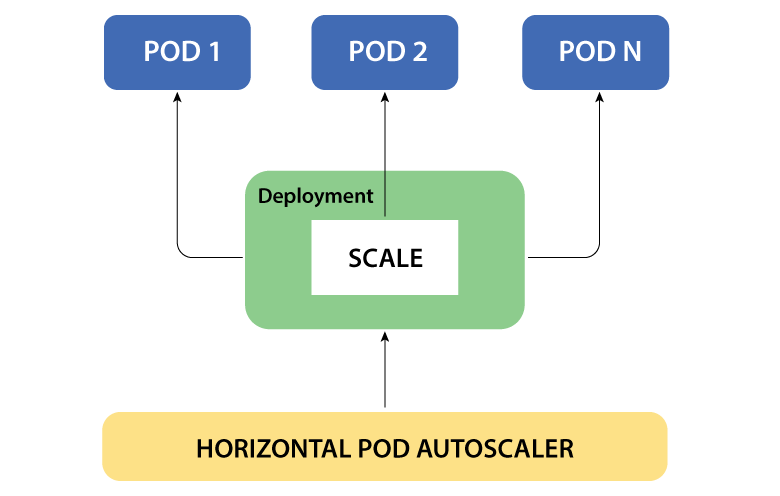
The HPA works by creating a controller that monitors the metrics of the target workload. The controller then uses these metrics to calculate the desired number of pods for the workload. If the current number of pods is less than the desired number, the controller will create new pods. If the current number of pods is more than the desired number, the controller will delete pods.
Note: The HPA controller runs periodically, so it may take some time for the number of pods to change after the metrics have been updated.
How to set up horizontal pod autoscaling?
Configuring HPA in your Kubernetes cluster involves several steps:
1. Enable metrics server: Ensure that you have a metrics server installed and running in your cluster. The metrics server collects and exposes resource utilization metrics.
2. Create HPA: Define an HPA resource in your Kubernetes configuration, specifying the target metric, target value, and scaling thresholds.
3. Deploy a metrics provider: If you want to use custom metrics, deploy a metrics provider like Prometheus to collect and expose these metrics to HPA.
4. Monitor and tweak: Continuously monitor your application’s performance and adjust your HPA configuration as needed to fine-tune scaling behavior.
To set up horizontal pod autoscaling, you need to create a horizontal pod autoscaler (HPA) object. The HPA object specifies the target workload, the metrics to monitor, and the desired number of pods.
You can create a HPA object using the kubectl command-line tool or the Kubernetes API.
Scaling deployment based on CPU utilization with HPA:
Suppose a company has a website that experiences spikes in traffic during certain times of the day, such as during peak business hours or when there is a major news event.
- The company uses Kubernetes to deploy and manage the website.
- The company configures horizontal pod autoscaling to scale the number of pods for the website based on CPU utilization.
- When the website is experiencing high traffic, the HPA will scale up the number of pods to ensure that the website can handle the load.
- When the traffic decreases, the HPA will scale down the number of pods to save resources.
This use case demonstrates how horizontal pod autoscaling can help ensure that a Kubernetes application is always running at its optimal performance level. By scaling the application up or down based on demand, the company can avoid overprovisioning resources and save money on their cloud bill. Let’s see the workings of this use case:
1. Create a basic deployment to serve as the target for autoscaling. Save this as app-deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-app
spec:
replicas: 3
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
spec:
containers:
– name: sample-app-container
image: nginx
2. Apply the deployment:
kubectl apply -f app-deployment.yaml
3. Create HorizontalPodAutoscaler:
Create an HPA resource to specify the autoscaling behavior. Save this as app-hpa.yaml:
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: sample-app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: sample-app
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 80
4. Apply the HPA:
kubectl apply -f app-hpa.yaml
5. Testing the Autoscaling:
To test the autoscaling, you can simulate load on the deployment. One way to do this is by using a tool like hey, which generates HTTP requests. Install hey and send some requests to your sample app:
# Install hey (assuming you have Go installed)
go get -u github.com/rakyll/hey
# Send requests to the app
hey -z 30s -c 20 http://
- The HPA object has three main parameters:
- The HPA also has a targetCPUUtilizationPercentage parameter, which specifies the desired CPU utilization for the target workload. If the CPU utilization of the workload is below the desired value, the HPA will scale up the workload. If the CPU utilization of the workload is above the desired value, HPA will scale down the workload.
- The HPA can also be configured to scale based on other metrics, such as memory utilization or the number of requests per second.
- The HPA controller runs periodically, so it may take some time for the number of pods to change after the metrics have been updated.
oscaleTargetRef: This specifies the target workload that the HPA will scale. This can be a deployment, a stateful set, or another scalable resource.
ominReplicas: This specifies the minimum number of pods that the target workload should have.
omaxReplicas: This specifies the maximum number of pods that the target workload should have.
Conclusion
Horizontal pod autoscaling is a powerful tool that can help you to ensure that your Kubernetes applications are always running at optimal performance level. By scaling your applications up or down based on demand, you can avoid overprovisioning resources and save money on your cloud bill.
Softweb Solutions has a team of DevOps experts who can help you with containerization by leveraging Kubernetes. Contact us to learn more about how HPA works and how you can use it to scale your Kubernetes applications.
Co-author: Anshita Solanki