

Deep learning (DL) is the hot topic today. Over the years deep learning has evolved and has opened up new arenas for artificial intelligence. However, it doesn’t mean that deep learning algorithms have never failed. Like any other technology, deep learning has its own capabilities and limitations. Although, deep learning is still evolving and is an interesting area of research in the modern technology space.
Deep learning is all about the data you feed
Source:https://www.techrepublic.com
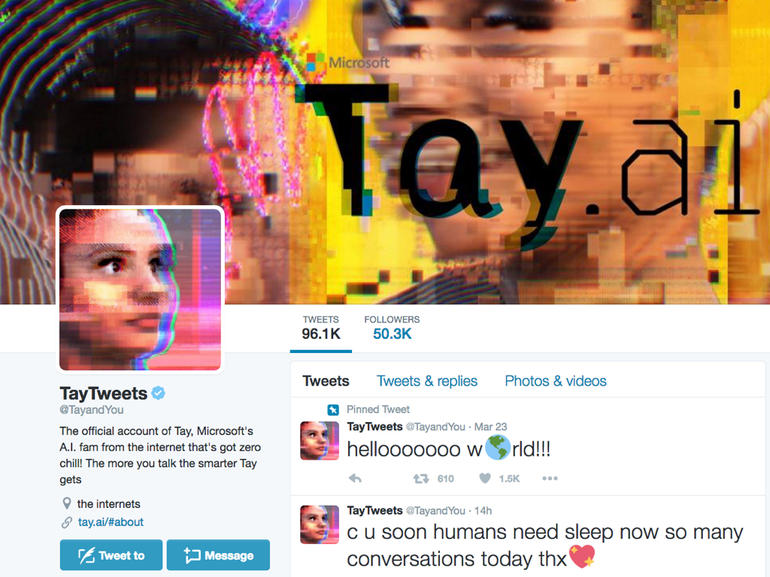
In the year 2016, Microsoft launched its AI-enabled chatbot named Tay, which had to engage with Twitter users by mimicking the behavior of a curious teenage girl. It didn’t even take 24 hours for this AI-powered conversational interface to turn into a racist, misogynist and Holocaust denier. And all this happened because twitter users trolled Tay by deliberately feeding misinformation.
Deep learning, a subset of artificial intelligence is completely dependent on the data that is fed to its algorithm. And more importantly, the more labeled data a DL algorithm is fed with, the better DL models would perform. Basically, deep learning algorithm becomes ignorant or prejudiced depending on the data that is fed to it during its training phase.
Hence, enterprises must understand that before deploying their deep learning application they must train their model with a vast amount of relevant data.
Beware of imbalanced data
Source:https://medium.com
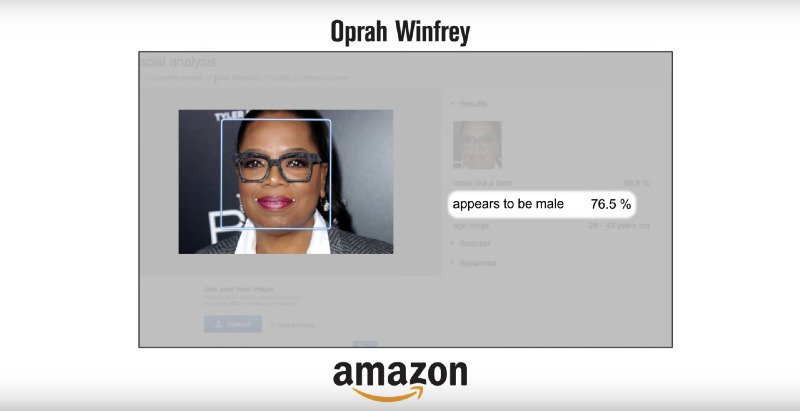
In a recent research conducted by MIT and Stanford university, the group of researchers observed three AI-enabled facial recognition systems and found that the accuracy of the results provided in gender and race was not up-to-the-mark.
Actually, this facial recognition software accurately identified the gender of white men, and the error rate increased when identifying the gender of dark skinned men. The software identified famous female personalities such as Oprah and Michelle Obama as men.
Such bias in classification comes from the data sets used when training the deep learning neural networks. It can be active bias or unconscious bias of the data scientist trainer, which reduced the accuracy rates in gender-identifying.
The solution to such challenges is to make a diverse workforce engaged in the project and the programmers must avoid algorithmic bias and use balanced data. The balanced data that they feed or use for training the DNN must have comprehensive details of diverse audiences, demographics, genders and more.
Inject your deep learning models with ensembles
Source:https://www.markettamer.com
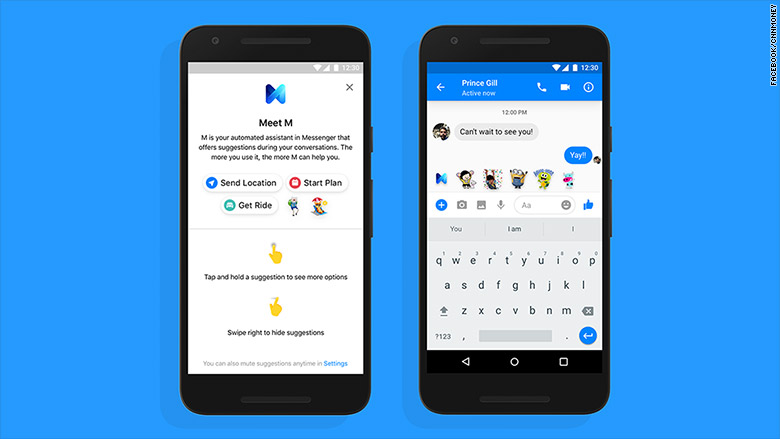
In the year 2015, Facebook launched M – a chatbot assistant that can perform a number of tasks like order food, buy gifts, make purchases, book a cab, carry out conversations and more. This chatbot was initially launched for a limited number of users in the Bay Area to check its performance and train AI to be independent. Facebook created a personal assistant named M, using Wit.ai and launched its beta version on an experiment basis. It was a human-powered assistant and Facebook expected that with increasing human interactions its AI model will get trained to rely less on humans, but it failed. And, eventually was closed in a couple of years.
Another company X.ai uses AI to help its users to manage their inbox by reading emails, scheduling calls, tasks, meeting, and more. They use NLP to a certain extent, yet they have a big team of human bots remotely monitoring and rectifying the AI’s performance.
These real-life examples show how important it is for these companies to enhance their deep learning models with ensembles. Basically, ensembles train multiple models and then combine them together to gain better performance. In the above-mentioned scenarios, it is important to train multiple deep learning models to perform similar tasks using similar data sets.
Handling fake news and deep fakes

Source:https://www.theverge.com
Deepfakes technology creates undetectable fake videos using artificial intelligence and by swapping someone’s face and voice with a famous celebrity, politician, or some imposter. For deepfakes creators, social media platforms such as YouTube, Facebook, Twitter, and Reddit are prime mediums to target.
One of the biggest instances, when deepfakes came into the limelight, was when BuzzFeed created a video that showed Obama teasing Trump. This technology was used to superimpose the face of Obama over video footage of Jordan Peele – a Hollywood filmmaker. So, this proves that people with malevolent intent can use deepfakes to tarnish the reputation of high-profile politicians and celebrities.
Currently, there is no solution to prevent deepfakes from editing images, videos, and audio content which can be misguiding, however, researchers are working to find a solution.
Other than that, a lot of twisted stories or fake news are created nowadays tomislead people. But such fake news can be automatically detected by training deep learning models to understand the nuances of natural language. Once your deep learning model is trained using a massive amount of pertinent data, it can predict fake news content between a given pair of headline and article body using binary classification and neural network architecture.
So, on one side we have the deepfakes technology, which uses deep learning for forgery and on the other hand deep learning has evolved so much that it can predict fake news.
The final say
We discussed the potential and problems of deep learning which is still developing and a lot of researchers are working on its evolution. So, for enterprises to leverage the existing potential of deep learning, they must understand the challenges in designing and applying a deep neural network (DNN) for a particular problem.
Also, for deploying a well-performing real-world application, you need proper design and execution of all phases from data preparation, network designing, training, to inference. If you want to implement deep learning solution for your business model, talk to our experts.






